Problémy s češtinou
přehled chybných zobrazení
Chybné zobrazení: ISO 8859-2 - Windows-1250 - ASCII - Mac - Dos - Kameničtí - Unicode - URL kódování - Sháním poznatky
Snažil jsem se shromáždit ukázky nečastějších chybných zobrazení počítačové češtiny. Tento přehled má význam obecný, ne pouze pro autory webových stránek, třebaže pro ně cíleně.
Má to sloužit jako pomůcka pro zjištění, co je s češtinou v konkrétním případě v nepořádku. Samozřejmě to není úplné. Někdy se vyplatí prozkoumat rovnou tabulky kódování.
Jako ukázkový text se nabízel tradiční "žluťoučký kůň", ale s koňmi nemám žádné zkušenosti, tak jsem si sestavil text z vodáckého prostředí, obsahující všechny české diakritizované znaky: "Loď čeří kýlem tůň obzvlášť v Grónské úžině." Doufám, že to nebude takový nezvyk.

Chybné zobrazení ISO
ISO-8859-2 je standardní kódování označované též jako Latin 2. V Microsoft Exploreru je označováno jako "středoevropské (ISO)". Je užíváno zejména na Unixu a Linuxu, ale též v mnoha Windows - aplikacích. Jeho podpora je velmi rozšířená.
Chcete-li, aby se ISO texty na Internetu správně zobrazovaly napoprvé, přidejte do hlavičky HTML souboru meta tag, který prohlížeči sdělí, že je to v ISO:
<meta http-equiv="Content-type" content="text/html; charset=iso-8859-2">
Nechcete-li používat meta deklaraci a můžete-li ovlivňovat http hlavičky (zejména programátoři), pak přidejte tuto http hlavičku:
Content-type: text/html; charset=iso-8859-2
Iso jako win

Nejčastější chybné zobrazení, postihuje znaky š, ž a ť, Š, Ž a Ť. Podle toho to vždycky poznáte. Řešením je přidání meta tagu nebo překódování do windows.
Iso jako Latin 1

Velmi časté chybné zobrazení, které nastávalo hlavně v Netscapu 3. Latin 1 je znaková sada západní Evropy, která nezná háčkovaná písmena. Všimněte si, že čárkované znaky se zachovaly, háčkované ne. Tato chyba se poznává podle malé jedničky, které se zobrazuje namísto š. Podle přeškrtnutého o namísto ř je zřejmé, že se nějakým způsobem jedná o Latin 1 (západoevropské).
Stejným způsobem se iso český text zobrazuje na terminálech, které očekávají západoevropský font (klasicky lepší unixové terminály, ty horší umějí jenom ASCII).
Iso jako DOS

Dos kódování se už moc nepoužívá, ale překvapivě často se zobrazuje tento rozsypaný čaj, pokud si někdo v prohlížeči IE zapne Automatický výběr kódu.
Špatný font

Zde chybuje autor stránek, který má na svém počítači nainstalován nějaký neobvyklý font v české verzi. Takový font v lepším případě na klientovi není (pak se to naštěstí zobrazí Timesem), v horším případě je font na klientovi pouze v anglické verzi, která neumí zobrazovat korektně české znaky. Jedinými bezpečnými českými fonty jsou Times, Arial a Courier.
Iso jako Unicode

Unicode skládá divná písmenka ze dvou znaků. Takže čeká za každým divným písmenem ještě jedno písmeno, se kterým chce utvořit dvojici. To druhé písmenko nezobrazí. Proto to vypadá, jako kdyby Unicode některá písmenka požíralo. Jakmile se tedy zobrazuje méně písmen, bude chyba v nastavení unicode, ať už je původní text kódován jakkoliv.
Ještě se dost často vidí jedna chyba. Pozná se podle toho, že místo písmene ž je řecké mí (μ). Takto jsou chybně kódovány výstupy programů, které jsou zobrazovány ve windows-1250, ale mají být v iso-8859-2 a zároveň ten program bere text psaný v iso-8859-2, ale chybně se o něm domnívá, že je ve windows-1250.
Chybné zobrazení Windows 1250
Windows-1250 je pro platformu Windows základní středoevropské kódování. Na jiných operačních systémech se příliš nepoužívá. V současnosti (2001) je tímto kódem psáno asi 70% českého netu. Internet Explorer nazývá tento kód středoevropský (bez přívlastků), což je poněkud nefér přístup.
Meta deklarace windowsovského kódování vypadá takto:
<meta http-equiv="Content-type" content="text/html; charset=windows-1250">
Windows-1250 jako ISO

Velmi častá chyba, způsobená nejčastěji přenosem textů mezi platformami. Opět jsou postiženy pouze znaky š, ž a ť.
Windows-1250 jako Latin 1

Velmi častá chyba zobrazení způsobená absencí meta deklarace. Prohlížeč se domnívá, že je text v západoevropských jazycích (latin 1). Jsou postiženy znaky ě, č, ř, ď ť, ů a ň. Obzvlášť dobře se tato chyba rozpozná podle toho přeškrtnutého o namísto ř a zachováním š a ž.
Některé anglické HTML editory běžně převádějí text tak, že vypadá jako by měl tuto chybu. Ve skutečnosti to podělávají, protože háčkované znaky nahrazují entitami (&něco;). Pak není pomoci, leda to (nejčastěji ručně) opravit.
Windows jako DOS

Překvapivě častá chyba při zapnutém automatickém výběru kódu.
Špatný font

Jedna ukázka z mnoha různých pohledů, které se naskýtají, když se autor designu snaží použít nečeský font.

Některé fonty páchají toto: anglické znaky zformátují, české nahrazují znaky z jiných fontů. Častý úkaz při používání systémových jmen fontů (např. fantasy, cursive apod.).
Windows jako Unicode

Výjimečná chyba. Totéž co u Iso jako Unicode.
ASCII
Pod pojmem ASCII se v českých zemích chápe verze textu bez háčků a čárek. To snad nemusím rozvádět. Připomenu jen, že omezování se na toto "kódování" je dnes už omezováním zbytečným, které pouze omezuje čtenáře. Fakt ale je, že není co zkazit.
Chybná zobrazení Mac kódování
Kódování češtiny používané na Macintoshích se v českých internetových luzích a hájích objevuje velmi zřídka. Uvádím ho spíše pro doplnění. Pokud na takovou stránku narazíte, nedá se s tím moc dělat, protože prohlížeče Internet Explorer neumožňují překódování. Ale Mozilla třeba ano.


PC Latin 2 aneb DOS aneb CP852
Windowsovské kódování pro DOS, víceméně historické kódování. Je potřeba dát
tam zápis
text/html; charset=CP852

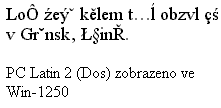
Kód bratří Kamenických
Historicky první elegantní kód prakticky zmizel z povrchu světa. Občas se v něm vyskytují některé staré texty. Výhodou je, že pokud se kamenické kódování zobrazí v Latin 1 nebo v PC Latin 1 (DOS), je to částečně čitelné.


Unicode UTF-8
Mezinárodní kódování, které obsahuje všechny znaky všech národních abeced používá pro kódování divných (neanglických) znaků dvojice bajtů = dvou písmen. Takže když se text náhodou zobrazí v jiném kódu, je z toho naprostý maglajs. Všimněte si, že každý diakritizovaný znak kreslí jako znaky dva.

Toto kódování se též označuje jako multibite (vícebitové) a multilingual (vícejazyčné), protože je obzvláště vhodné pro psaní vícejazyčných textů. V HTML se musí deklarovat takto:
<meta http-equiv="Content-type" content="text/html; charset=UTF-8">
URL kódování
Pro předávání formulářových dat HTTP protokolem bylo vyvinuto URL kódování, což není ani tak kódování, jako spíše transportní metoda. (Text je ve skutečnosti v tom kódu, ve kterém byla stránka s formulářem.) Někdy se ale následkem nějaké chyby její výstup zapomene dekódovat a uživatel se potkává se změtí procent. (Mezera je nahrazena pluskem. V novější verzi URL kódování je mezera %2* (kde * je nějaká další šestnáctková cifra, nejčastěji nula)):

Pokud jsou tam namísto procent rovnítka (a zachovány mezery), tak se jedná o tzv. quoted-printable kódování standardu MIME. Občas se s ním lze setkat v poště (chyba je pak u odesílatele, který má špatně nastavený formát odesílané pošty).
Sháním poznatky
Pokud znáte nějaké další problematické zobrazení češtiny související nějak s webem, pošlete mi prosím jeho popis.
Reklama

